
Knowledge graphs are becoming a key resource for global enterprises. The textual labels of a graph’s nodes form a standardized vocabulary. Unfortunately, knowledge solutions are often wastefully developed in parallel within the same organization, be it in different departments or national branches. Starting from zero, domain experts build application-specific vocabularies in a hard-to-use taxonomy or thesaurus editor, mostly only in one language. Yet enterprise terminology databases in many languages are almost always already available. Enterprises and organizations simply have to realize that they can use this treasure chest of data for more than just documentation and translation processes.
Mutual understanding: RDF and SPARQL
The problem is that legacy terminology solutions have proprietary APIs or special XML export formats. They also do not structure their concepts in a knowledge graph, which makes it hard to use enterprise terminology data for anything more than translation. Taxonomies, thesauri, or ontology products, on the other hand, don’t cater for cross-language use and thus remain local. Multilingual Knowledge Systems such as Coreon bridge this gap, but until now even this also required integration through proprietary interfaces, or the exporting of data.
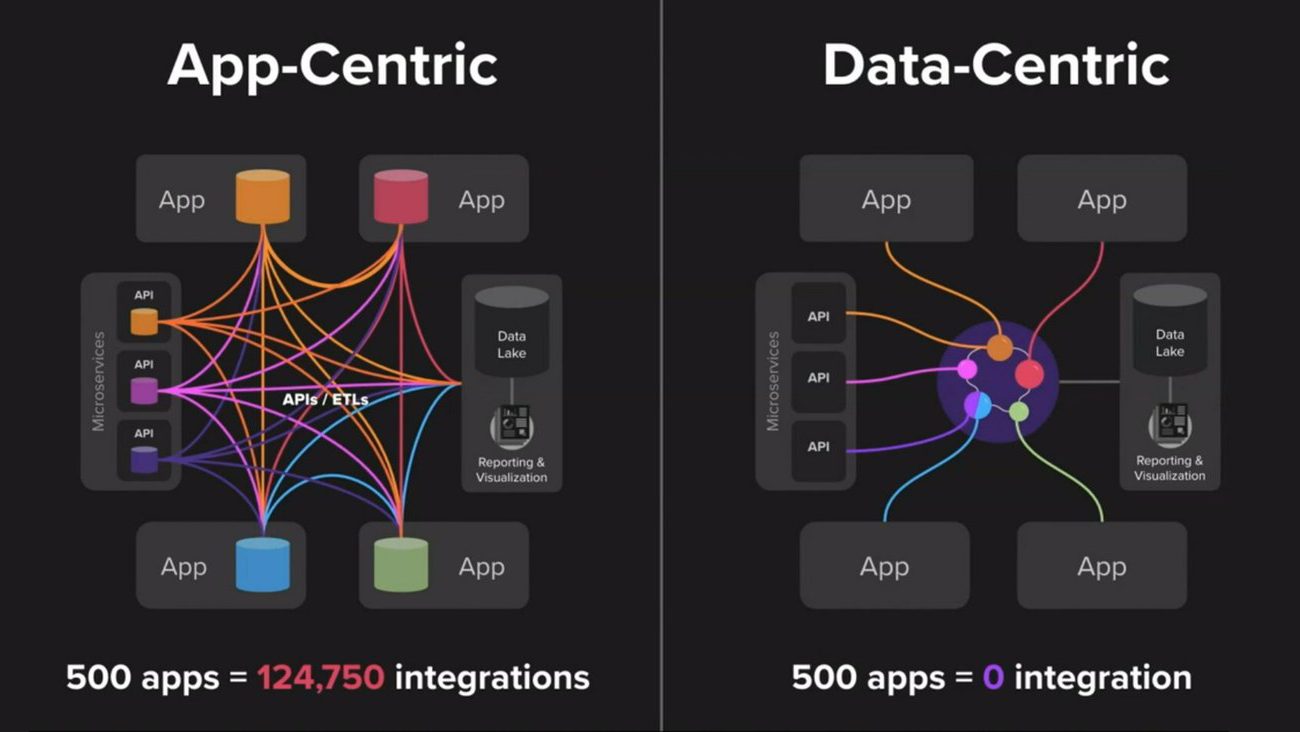
(App-Centric vs Data-Centric by cinchy).
SPARQL (the recursive acronym for SPARQL Protocol and RDF Query Language) makes it possible to query knowledge systems without having to study their APIs or export formats. Coreon was therefore recently equipped with a SPARQL endpoint. Its knowledge repositories can now be queried in real time using the SPARQL syntax, i.e. a universal language for developers of data centric applications.
Enterprises and organizations simply have to realize that they can use this treasure chest of data for more than just documentation and translation processes.
Semantic success
A central Multilingual Knowledge System, exposing its data via a SPARQL endpoint, thus becomes a common knowledge infrastructure for any textual enterprise application. This is regardless of department, country, or use case. For example: content management, chatbots, customer support, spare part ordering, or compliance can all be built on the same, normalized enterprise knowledge. In taking proprietary APIs out of the equation and with no need to export, mirror, and deploy into separate triple stores, real time access of live data is guaranteed.
Your organization already possesses this data. It’s just a case of maximizing its potential, introducing a cleaner and more accessible way of handling it. Contact us at info@coreon.com if you’d like to know more about how a common knowledge infrastructure can help your enterprise.
Coreon would like to extend special thanks to the European Language Grid, which funded significant parts of this R & D effort. The SPARQL endpoint will also be deployed into the ELG hub, so it will be reachable and discoverable from there.



